UCLA Basic Plasma Science Facility
The Basic Plasma Science Facility (BaPSF) is a US national collaborative research facility for fundamental plasma physics, supported by the US Department of Energy and the National Science Foundation.
The purpose of BaPSF is to provide the scientific community access to frontier-level research devices (principally the Large Plasma Device) that permit the exploration of plasma processes which can not be studied in smaller devices or are difficult to diagnose in larger facilities, such as magnetic confinement fusion experiments.
Meet the team
Latest publications
Read our latest publications here.
Laboratory generation of multiple periodic arrays of Alfvénic vortices.
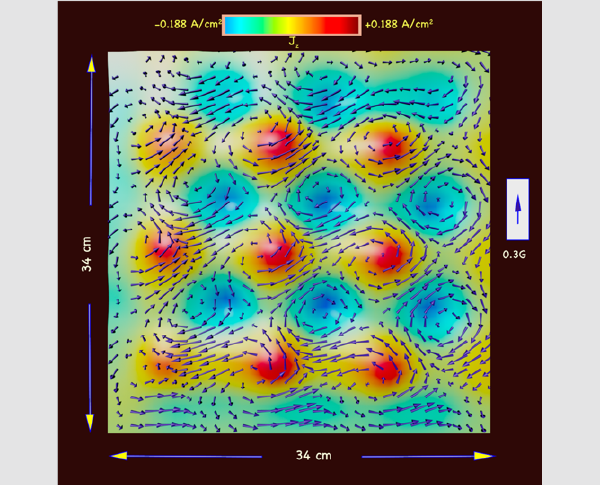
A novel antenna has been constructed to generate shear Alfvén waves with large k⊥ such that k⊥ ≃ 1 − 10 cm−1 The antennas comprise multiple current loops, aligned with their normals transverse to the background magnetic field. Each loop is a generator of Alfvén cones. The observed spatial pattern displayed is the interference of thousands of these cones. The magnetic field between dual antennas which have with different spacing of the current loops multiple wavenumber modes are observed. This type of antenna can serve as a platform for the generation magnetic Alfvénic turbulence. [submitted to Physics of Plasmas].
Three-wave coupling observed between a shear Alfvén wave and a kink-unstable magnetic flux rope.
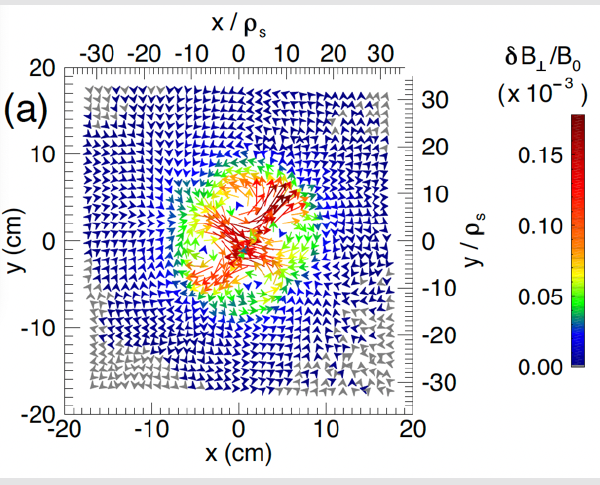
Snapshot of the spatial pattern of the magnetic field from a three-wave interaction between an Alfvén wave and a kink-unstable flux rope. The mode is the lower sideband (with frequency f_Alfvén-f_kink). This mode has an m=+2 pattern, whereas the primary waves have m=-1 for the Alfvén wave and m=+1 for the kink. [Adapted from Phys. Plasmas 31, 092302 (2024); doi: 10.1063/5.0217895.
Laboratory Study of Magnetic Reconnection in Lunar-relevant Mini-magnetospheres.
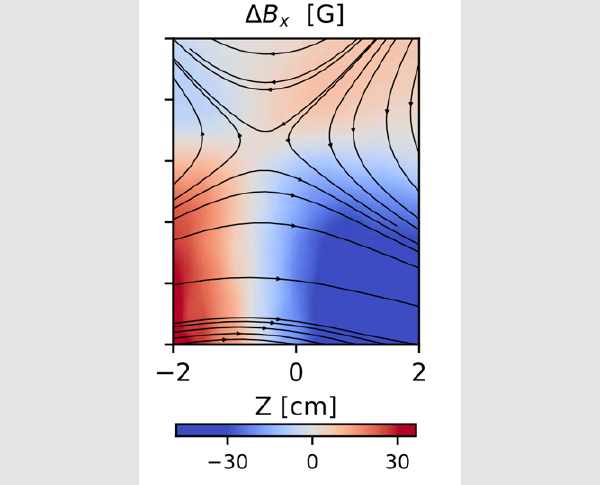
Out-of-plane dynamic magnetic field ΔBx in the reconnection plane. A quadrupolar shape of this magnetic field is observed around the x-point, which is a typical signature of Hall effects in reconnection, associated with spatial scales smaller than, or of the order of, the ion inertial length. In that case, the ions decouple from the electrons, leading to differentiated flows and thus currents that are the source of this structure. [Adapted from The Astrophysical Journal, 969:124 (8pp), 2024; https://doi.org/10.3847/1538-4357/ad4fff.
Wave coupling and propagation from a fast-wave antenna in the lower hybrid range of frequencies.
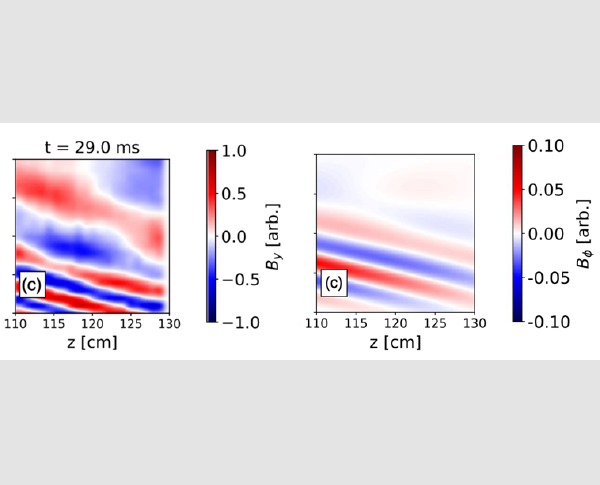
(Left) Data. Cross-spectrum measurements of the y-component of the wave magnetic field in the XZ plane for the 476 MHz, 0.2 T case. (Right) A COMSOL model run using nominal 476 MHz, B0 = 0.2 T case, m = 6. Density is representative of timing for the panel on the left: n0 = 1.5 × 10^17(m−3). [Adapted from J. Plasma Phys. (2025), vol. 91, E103; doi:10.1017/S0022377825000522 .
Videos
The Plasma Science and Technology Institute at UCLA consists of affiliated laboratories and research groups that investigate fundamental questions related to the fourth state of matter known as "plasma".
This video describes the Basic Plasma Science Facility in detail.
The Plasma Science and Technology Institute at UCLA consists of affiliated laboratories and research groups that investigate fundamental questions related to the fourth state of matter known as "plasma".